Large Language Models - Bridging Humans and Machines

LLMs are computer programs that learn how to use language—basically, like a super-smart version of autocomplete on your phone.
They could:
Read and write text
Help with learning
Take over boring, repetitive tasks
Quickly and effectively find information
In everyday life, these models feel like a bridge between us and the digital world—they help us communicate more easily, save time on tasks, and unlock new chances to be creative and learn new things.
The “bridge” role also raises questions about dependency: as people rely more on LLMs, critical thinking skills of some might weaken if we’re not careful, but that’s not the topic today.
So, how does this “very advanced autocomplete” work?
First of all, we need to gather Data.
LLMs are trained on huge amounts of publicly available data that companies get from:
Websites (e.g., blogs, news sites): These give models a wide variety of everyday language, opinions, and factual information. Forums and blogs are super useful because they show how people naturally talk and write.
Social media platforms: Social media platforms, and especially Reddit discussions, are such great training material because they mix casual conversation with in-depth knowledge. In fact, OpenAI signed a deal with Reddit to officially use its data, showing how valuable these conversations are to train the models.
Public domain archives and government pages: These provide trustworthy, factual content such as laws, statistics, and historical records. Because they’re public, companies can safely use them without copyright issues.
Coding related forums like GitHub: Code and technical discussions on GitHub help models learn programming languages and technical writing. That’s why LLMs can now generate or explain code.
Wikipedia and other educational content: Ensures models have access to general facts, definitions, and explanations across almost any topic.
But what if you run out of places to collect data? Web Crawlers!
A web crawler is like an automated explorer for the internet—it starts from one page, follows links to others, and collects information as it goes. This helps AI systems understand what’s out there online and collect as much data as they can. Crawlers generally respect a site’s robots.txt file, which is like a polite notice asking bots what they can or cannot visit. But some AI companies don’t always follow these rules, causing issues for content creators and publishers.
But how does an LLM work?
LLMs use a structure called a transformer architecture, which allows them to process entire sentences at once and understand the relationships between words. This process helps them understand grammar, context, meaning, and the general idea of how words work. So then, when you ask a question or give a prompt, the model predicts the most likely next word or phrase based on patterns it learned during training.
So now, when your general LLM is ready, what most companies do is Fine-Tuning.
Fine-tuning is just taking a model that already knows a lot and teaching it extra stuff for a specific job—not to start from scratch. Instead of retraining the whole model, you tweak it a bit with your own data so it becomes great at exactly what you need. This makes it faster, cheaper, and more accurate for specialized tasks like legal summaries, customer support, medical assistance, market analysis, etc.
Why Fine-Tune?
Domain specialization (e.g., legal or medical terminology): Fine-tuning turns a general model into a specialist.
Improved task performance: You’re not getting answers—you’re getting the right kind of answers.
Cost-efficiency vs. building new models: Fine-tuning takes a model that’s already smart and makes it smarter for your needs.
Keeping outputs current and relevant: General models can go stale—like a reference book that hasn’t been updated. But when you fine-tune your model with fresh, relevant data, it stays knowledgeable and useful with the latest info.
The Privacy Problem with LLMs
First of all, what’s Privacy?
It’s simply having the right to keep parts of your life just for yourself—like a private space where you're not being watched or listened to. It’s about choosing what personal things you share and with whom.
Everyday Example:
Imagine you're waiting for a call from your recent job interview, and out of nowhere, your personal number gets posted in a public Facebook group—right there for anyone to see, only because the event organizer thought it would be helpful to share your contact details. Without asking you first! That’s more than awkward—it’s a privacy breach. All of a sudden, you get exposed to unwanted calls from people you might not even know. Your personal space gets invaded, and your peace of mind gets disrupted.
The Threats of LLMs
LLMs are posing a huge variety of different threats, but the ones that we are going to talk about today are:
Memorization: When an LLM repeats exact pieces of its training data—like a sentence or number—without fully understanding it.
A while ago, there was a case involving StarCoder (an open-source coding LLM) that revealed that about 8% of its training samples were memorized. With just the beginning of a prompt, the model often completed it with nearly identical content to the original training example.
Prompt Injection: Someone tricks an LLM by embedding misleading or malicious instructions in the input, causing the model to produce unintended or unsafe responses. Both of those are huge risks, but yet it’s only on paper, as not a lot of people have heard about the huge scandal with one of the most popular datasets.
The LAION Dataset
The LAION-5B dataset, a huge collection that was used to train AI image generators like Stable Diffusion and Midjourney, ended up including private photos of children, often from family blogs or unlisted YouTube videos that weren’t meant to be public. These images sometimes revealed sensitive details that were absolutely not meant to be spread or shown to the public, like a child’s name, age, school, or even address.
Researchers from Human Rights Watch discovered that even though many of these photos were never indexed by search engines, they still got swept into AI training data without consent.
The worst problem that comes with non-anonymized data is that once it is absorbed by a model, it can’t simply be undone—even if it’s later removed from the dataset. This means people’s private moments could continue to be used by AI in ways they never agreed to.
Building Defenses
In order to better find out the opinion and awareness of the public on this matter, I decided to conduct a small survey in the centre of Reykjavik.
Overall, there were four questions:
Do you use Chat GPT (or its variants)?
Do you feel confident entering your personal information, such as phone number, age, passwords, marital status, etc.?
Are you aware of any confidential information leaks related to LLMS? Telling the person about the LAION-5B leaks.
Would you change your behavior now that you know this?
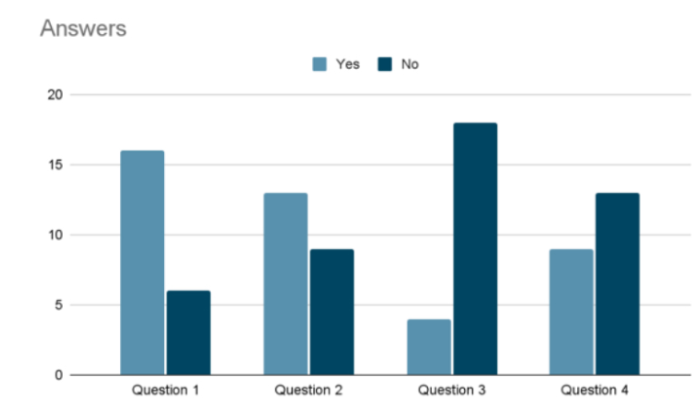
From looking at the graph, we could see that a huge amount of people are actually sharing their personal details with LLMs.
What's worse is the amount of people who are not even aware of the consequences that they might have to deal with, and the risks that they are facing.
Knowing all that, a question comes up:
How Can We Protect Our Privacy?
There are only four main rules that you should go with when trying to maximize the level of security of YOUR own LLM or the LLM that YOU are using.
Input/Output Filtering
Think of this as a security guard at the door. It checks what goes in (your input) and what comes out (the model’s output).
For example, if someone tries to feed in a phone number or if the model tries to give one out, the filter blocks it. Crucial because once private data is inside the model, it cannot be removed.
Adversarial Learning
Humans give feedback to guide the model, teaching it to ignore harmful or sneaky instructions.Operational Design
Building systems with privacy in mind (least access, strong authentication). It means setting rules like: “Only the right people can use it” or limiting access to it.Monitoring & Logging
Continuous tracking to detect misuse or suspicious queries.
Final Reflection
When we build LLMs, we're not just engineering machines—we're shaping how humans and technology converse. It’s a delicate balance: with every advance, we gain power and convenience—but also responsibility. How we protect privacy today isn't merely about safety—it’s about preserving our ability to choose who we are in a world that’s always watching.